
 RSMUS.com
RSMUS.comOver the last ten years, the uptick in natural and manmade disasters has placed disaster recovery and business continuity at the top of the list of things that keep IT executives and CFO’s up at night. The practice of preparing your organization for a disaster is often overwhelming due to the number of systems, departments, and individuals that need to be included in the planning process. In addition, it is also costly because of the infrastructure required to support an effective solution as well as the resources needed to plan, implement, and maintain the solution. As a result, disaster recovery initiatives are often poorly planned and under budgeted.
Disaster recovery planning and business continuity are often muddled into the same project and create unnecessary and additional headaches for IT departments. Although they have the same goal, which is to implement procedures that protect the business from disruption, they each have a specific focus. An organization cannot have one without the other and there are important differences that should be noted between the two. Business continuity touches upon the “people aspect” of disaster recovery planning and addresses questions such as:
- What is our communication strategy to notify our employees and customers that a disaster has been declared?
- Where will our employees work if their primary office is inaccessible?
- Have we performed a business impact analysis to determine which services are mission critical to our business?
- How are we going to protect and recover our data?
- Have we documented steps to deal with various disaster scenarios such as extended power loss or flooding?
Disaster recovery planning deals directly with the technology and infrastructure that supports protecting and recovering business operations. The four pillars of a disaster recovery plan include:
Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO)
The RPO is where an organization determines a time period for an acceptable loss of data. For example, if an organization determines that an hour or more of data loss is unacceptable than the technology solution required to accommodate this requirement is dramatically different and more costly than the solution designed for 12 hours of data loss. The RTO is the time in which a business process must be restored after a disaster is declared. Disaster recovery planners will often create a service catalog where all business services are listed and prioritized according to their core functionality. For example, e-mail and financial data are often listed as core by most organizations and require a more robust disaster recovery solution than secondary services such as printing.
Scope
The disaster recovery scope includes strategies that will be employed to protect and recover an organization’s data. For example, if an organization’s server environment is 100% virtual with multiple office locations, the strategy will be different than an organization that has a single location with multiple physical servers and no virtualization. Vendors are making it easier for customers to design a solution that meets the business requirements. It is first important to know what those requirements are and second, is the solution scalable for the growth of data in the organization. Backup solutions fall into the following three categories:
- On premise – The solution is designed around a traditional backup design and is housed onsite and stored on tape which is kept offsite.
- Cloud – Multiple vendors now exist in this space that offer a service based solution in which data is stored locally on an appliance and replicated to the vendor’s data center.
- Hybrid – The hybrid solution leverages a traditional on premise solution but data is replicated to a secondary site where organizations can failover to in the event of a disaster.
Documentation
Organizations should establish standards for defining how the documentation that is to be maintained as part of their disaster recovery plan. The standards should include: a systems overview, a summary of recovery strategies, restoration procedures, and resource requirements. As result, a run book is created for each core system. It is also important to note where the documentation will reside so that it is easily accessible by authorized personnel in the event of a disaster.
Testing
Testing a disaster recovery plan is of the upmost importance. The test case should be a formal test program that includes multiple critical systems. At least once a year, a full disaster recovery test should be scheduled. Single system recovery tests, such as e-mail, should be scheduled more frequently. An additional benefit of testing a disaster recovery plan is it provides organizations the opportunity to hone their existing disaster recovery documentation and insure their staff are prepared if a real disaster where to occur.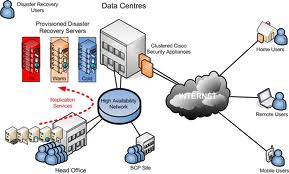
Now that we have explored the various facets of disaster recovery and business continuity, you are probably asking yourself where do I start? Here are some high level steps you can use a guild for building a comprehensive disaster plan.
- Start with a business impact analysis to identify your critical data and services as well as establish RTO/RPO
- Design a solution that meets the requirements determined from the business impact analysis
- Document the recovery steps for each core service including system dependencies
- Train staff on procedures and processes to recover the business in the event a disaster occurs as well as steps to fail back when the disaster has subsided
- Establish a communication strategy to notify employees and customers
For more information on disaster recovery planning and business continuity, contact McGladrey’s technology consulting professionals at 800.274.3978 or email us. In addition, please check out our services offerings on our website.
By: Rich Knoerzer – RSM LLP