
 RSMUS.com
RSMUS.comAX2012 R2: Retail POS Database Sizing
From time to time I am asked what version of SQL Server the client should use for their store database. Of course, the answer that everyone is looking for is “SQL Express”! This is also “supported” by Microsoft but they have not (to my knowledge) every directly recommended using SQL Express in the store. The answer to the question often boils down to sizing the database for the implementation but it also depends on how you plan on maintaining the remote databases.
From a client’s perspective, the SQL Express version is attractive because it provides a lot of value for a very low price (free). This is especially true for retailers that have many stores as the compound cost of database software licensing would quickly become cost prohibitive.
I have been implementing Microsoft store systems for over 12 years, first with LS Retail and NAV using SQL express and now with Microsoft Dynamics AX and the AX POS. The use of SQL Express requires careful planning and consideration for ongoing maintenance and an understanding of how the database will grow.
Ongoing Database Maintenance
The reason why database maintenance is so important is that, over time, the database will become fragmented and slow. Because SQL Express only allows a single cpu (or four core) and is limited to 1GB of RAM, the onset of this problem cannot so easily be covered up with hardware. We have seen scan times increase from sub one second to over four seconds due to this kind of fragmentation.
With SQL Express, there is no database maintenance tooling to assist in the completion of tasks such as re-indexing, checkdb, backing up and shrinking the database. If we had SQL Standard edition, we would be able to setup a maintenance plan in a few clicks.
These maintenance tasks seem like trivial things but when you have a retailer with hundreds of stores (read: 100s of remote databases), this becomes overwhelming. This problem can be solved by some careful scripting running on task scheduler and many of our RSM clients benefit from this capability. We even have logs that are shipped back to HQ so we can determine if the scripts are running.
Make sure, if you decide to go with SQL Express, that your implementation partner has a good strategy for maintaining the remote databases. Otherwise, this problem will crop up soon after you go live, leaving you to scramble for a solution.
Sizing Your Database with SQL Express
SQL Express is limited to 10GB in size. When you first implement the system this is typically not an issue. However, you will not have to wait very long for this to become a big firefight because the database can grow at a tremendous pace. Make sure that you understand how your data replication is initially setup and how the data will change over time. This understanding can really save you a lot of hassle.
Some consideration should be given to the way that replication is designed. Things have significantly changed, between AX2009 and AX2012 but the initial setups provided by Microsoft have not. In AX2009, things were relatively straightforward from a table standpoint. You could pretty easily determine what tables were driving what area. When AX2012 came along, the database normalization that occurred in AX2012 has added a significant number of tables. If you compare the behavior of an AX2009 POS database to an AX2012 POS database, the amount of records and database required to complete the same set of tasks has grown over 30%. Although Microsoft keeps raising the size limit for the Express database, it should not be your strategy to hope for this change each year.
If you are new to the Microsoft Dynamics AX POS world, you probably ran the initialization, hooked up your Data Director / Store Connect / CDX and then let the replication go. Early on we found that there were significant shortcomings in the replication model that Microsoft provides with the “initialization” process. There are typically missing fields and even sometimes missing tables. Most of that has been shaken out by AX2012R2 but there are still some significant issues that remain. You should understand these issues prior to undertaking a sizing exercise. This understanding may provide alternatives that you can use to keep costs down in your implementation.
SEND’EM ALL!
The primary strategy that is used by the Microsoft is to send every record in a table to every “distribution” group. This means that every store database will have every customer, every item, etc. There are five main areas to consider when setting up replication:
ASSORTMENTS
The standard replication setup provided by Microsoft will send every assortment for every store to every single distribution location. This means that if you have 100 stores and a 1,000 items, you will get 100,000 records that define the assortment sent to every store. In addition, the replication will still send every single item and all of the related tables, whether the item is in the store’s assortment or not. This is a good thing, allowing for cross store returns, but you should understand this when sizing the store database.
ADDRESS BOOK
The DirPartyTable and its related entities (You know you love it), house all of the master entities and their addresses in one giant address book. This entire table and the related tables is sent to every store. If you implement HR for your company and AP, this means that the ENTIRE employee address, vendor address, contacts (prospects), customer and every organizational unit will be sent to every store. Of course, most people just want the customer addresses.
So, you see, as an added bonus, we get to maintain all of this extra, unneeded data in your store database. This extra data is consuming space that counts towards your 10GB limit. With some work, the information in these tables can be limited so that only relevant records are sent.
ITEM IMAGES
With AX2012, Item images were introduced and they really look great at the POS. But, if you have a large number of items, this feature is going to cost you a large amount of space because all of these images are stored in the database.
ITEM ATTRIBUTES
Another nice feature is item attributes. About the only place that this feature is used other than on the website is on the Product Details screen on the POS application. There is a little, undersized panel that appears on that screen that allows you to scroll through the various attributes that are setup for the item. There is a pretty high cost to the attribute data which is very strange because you would think it would be a pretty simple table structure. However, there are about 11 tables included in setting up item attributes. To add insult to injury, the tracking tables required by offline mode for this actually take up more space than the actual data. There is more about offline mode next.
OFFLINE MODE
But wait, there’s more. Another feature that Microsoft added with AX2012 is the “offline mode”. Offline Mode functionality allows each POS to “subscribe” to the main store database. The main store database then “publishes” to each of the POS terminals. This is a synchronization model that is supported by Sync Services for ADO.NET. In order to support this model, there are a couple of methods used to figure out what changes have occurred. Microsoft has implemented the model that provides a “tracking” table for every table that is monitored. You setup the specific tables that are monitored in your Offline Profile in Dynamics AX. If you use the standard configuration, the offline profile adds 215 additional tables to the database. These tables almost double the data requirements on an ongoing basis. This means that if you have data storage figured out to house 10,000 items, you will need about double the amount of space to support the offline mode.
You may be able to cut back on the number of tables required depending on your comfort with limited functionality while in offline mode but the fact is that it will require a significantly higher amount of storage if you choose to implement offline mode.
Another thing to understand is that the tracking tables never get truncated. Even though the Sync Services model supports the maintenance of these tables, the tracking data will increase forever. You will need to write your own truncation routines.
SIZING MODEL
Now that you have some background, I want to turn to the model that I use when sizing a database. This model is not complicated to setup but it requires an understanding of the POS database and how that database will be setup in order to use it.
1. DETERMINE MODEL RECORD SIZES
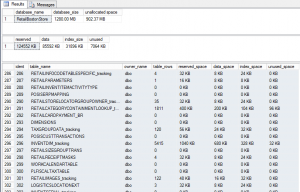
As an example, you can use the POS database that ships with the Microsoft VPC. If you run the following SQL Script against the database, you will get a picture of where the data is for initial setups. I did not write this query. (Credit goes to Derrek Leggett’s post on dbForums).

This will result in the following dataset. If you look closely, you will notice that some of the tables end with the string “tracking”. These are tables that are added when the offline mode is enabled.
2. DETERMINE BASE DATA, GROWTH DATA AND GROWTH DRIVERS
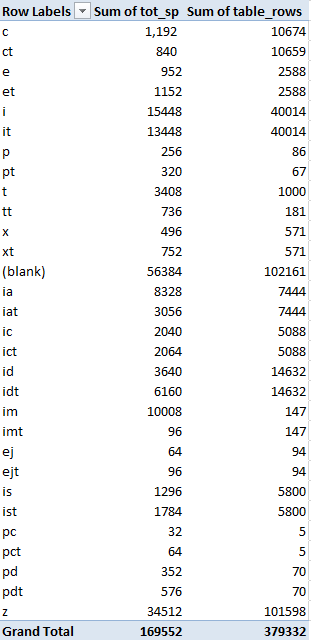
Copy the results of the third query into an excel worksheet. You will need to parse the columns to remove the “KB” in the string for the results. After you do that, add up the reserved space, data space and index space to get a total space. Next, mark each record in the list according to their table group so you can produce a pivot table (see below):
I used a notation for the table groups: c=customer, e=employee, i=item, p=price, t=transaction, x=tax, ia=item attribute, ic=item category, id=item dimension, im=item image, ej=job, is= assortment, pc=discount codes, pd=discount offers. In the case when there is a “t” at the end of the notation, this represents the tracking table that is created and directly related to the master table. I notated both so that you can determine the impact of turning the offline mode on and off. The number of records is really not important, we are ultimately trying to get to a number of kb / record so we can see how the database scales.
Each table can be characterized as either “setup”, “transaction” or “master”. Records related to setups will not change much but there is a large initial data size to get it up and running. In my current model, there is as much as 90MB of data required just for setups. Transaction records relate to the actual POS transactions that get created for sales, logins, returns, tender declarations, etc. The size of this data set is directly related to how much history the client wishes to retain prior to truncating it. The amount of history is usually double the return policy. So for a 30 day return policy, I would keep 60 days of history and truncate the rest.
Side Note: Microsoft has provided some functionality to truncate the transaction tables but it is an incomplete implementation. The RetailTransaction table is not included in the truncation and will grow indefinitely unless you take steps to truncate it yourself. The assumption I use in the model for transactions is that they will grow to a certain point and then stop growing, because I will be truncating them.
The last “type” of table is the master tables. Master tables are tables (or their required relations) that store items, prices, and customers. I actually split this out further so that I can better scale the database based upon what is driving the growth. There is a distinction you will need to make around the dirparty table because not all of these are related to customers and customer growth rates. I use the following groupings: Customer, Employee, Item, Item Attribute, Item Category, Item Dimensions, Item Images, Item Assortment, Pricing, Offer Codes, Taxes and Promotions.
Each of these groups have a driver. For example, the group of tables related to customer is driven specifically by the number of customers in the database. In my model, I have determined that the customer table group requires 48kb for standard data, an additional 34kb for offline tracking data for each customer record. That means if I know the number of customers my client has, I can multiply that by 48kb (77kb for offline mode) to determine how much space the customer data set will take.
After you have a good understanding of the data size of the table group for each area, you can apply a driver to the group. In the example below, the driver is represented by the “scaling reference table and scaling table records in sample”. For the customer group, this meant dividing the total non-offline data for the customer table group (see pivot table exhibit above) 1,192, divided by 25, the number of records in the Custtable (see Scaling Table Records in table below) =47.68kb per customer record.
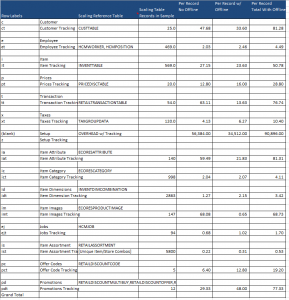
The way to interpret this is that for each customer I add to the database, I will add approximately 48kb to the database provided offline mode is not enabled.
It is important to understand the subtleties of different retailers for this model to be effective. For example, a soft goods retailer will have many more item dimensions and will also have base price markdown records than a hard goods retailer. Understanding these differences comes with experience.
The following screenshot shows how the model can be constructed from the different table groups. Rows highlighted in green represent inputs gathered from the retailer. Please note that the data in this table is just an example.

3. GATHER INPUT FROM RETAILER
Once the base data, growth data and growth drivers are established, additional information is required to “fit” the model to a specific retailer. You will need to collect information to determine the initial number and annual growth rate of Growth Driver records for each data area for input into the model. Consider how the implementation may be different than your model database and make the appropriate adjustments.
4. MODEL THE GROWTH OVER A PERIOD OF YEARS
After all of these inputs are in place, you will be able to model the initial size of the database and see how it will grow over time. You can see where the database will exceed the SQL Express database size limit and determine whether this is an acceptable horizon or not. If it is not an acceptable horizon, consider how you can better tune the replication model to limit the data being sent to the store database and adjust your model accordingly. Below is a snapshot of a growth model I have done that shows the database exceeding the capacity of SQL Express somewhere in year 3. In this case, I have offline mode enabled.
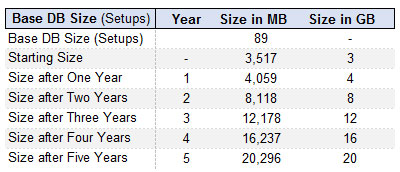
Using the same exact model inputs, if I turn off the requirement for an offline database, I get the following result. The database will exceed capacity somewhere between year four and five.
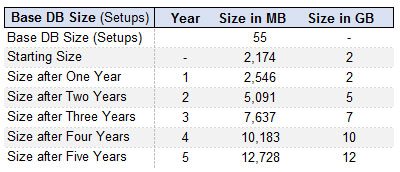
As you can see from the example above, additional work is required to tune the replication properly to ensure long term viability of SQL Express past year four. Make sure your implementation partner understands how to manage this. If you don’t, your only recourse may be to make a very large investment in database licensing in your near future.
Conclusion
SQL Express is very much a viable choice for use in a retail store environment. Retailers and implementers seeking to implement SQL Express should understand how the database works and how the retailer plans to implement their system. SQL Express requires additional work related to database maintenance and also tuning of the replication model. Understanding how much work is required and whether it will be an issue for your implementation is key for a successful Dynamics AX POS project.
Disclaimer from the Author: I have included some specific examples in this document that some may rely on to make decisions about sizing the database. The information in this document does not come with any warranty, express or implied and should not be used as the basis for any business decision. Use at your own risk!
RSM Staff
RSM empowers middle market companies worldwide to take charge of change. Our unique middle market perspective makes RSM the natural choice for growth-oriented, internationally active organizations seeking relevant insights and tailored, innovative solutions for a complex and changing world. With a global reach spanning more than 120 countries, we instill confidence in a world of change by bringing the full power of RSM to make a lasting impact on our clients, colleagues and communities.